





文|王磊 刘雅杰
编辑|秦章勇
默不作声的智己,开始在智驾上憋大招。
50多页的PPT,42分钟的讲解,全是硬核的智驾技术干货,就为了展现出一个主题,智己汽车和Momenta联合打造的智驾大模型IM AD 3.0,已经进化到下一个阶段——拥有人的直觉。
“直觉”这个词,也是贯穿整场发布会。
关于端到端,每家企业的研发路线都不尽相同,解释的话术也有所区别,IM AD 3.0的优势,则是用直觉来形容,其背后靠的则是一段式端到端直觉式智驾大模型。
这套大模型拥有类似人脑结构的思考方式,驾驶过程中会生成本能反应主导的直觉决策能力,也就是老司机的开车方式,所以智己毫不客气地表示自家智驾就是“十年老司机”。
除此之外,基于IM AD 3.0,智己还成为了国内首个,同时具备L2、L3、L4级智能驾驶量产能力的品牌。
开车靠“直觉”
智己CEO刘涛也顺势公布了L2到L4的时间表:

L2+级高阶辅助驾驶,已于本月在全国范围内开通全系车型“无图城市NOA”,可以做到“全国都好开、全场景都敢开”。
智己还启动了欧洲市场的L2+道路测试,目的是为了打造一个“全球都能开”的无图NOA。
L3级自动驾驶已进入量产倒计时,今年6月,智己入选国家首批智能网联汽车L3级自动驾驶准入和上路通行试点名单,预计将于2026年正式具备L3级自动驾驶方案的量产条件。
同样位于智驾第一梯队的问界、小鹏暂不在该名单中。
另外,智己预计将在年内获得首批“L4级无驾驶人道路测试牌照”,智己无人驾驶车将很快实现上路。

和大部分车企不同,智己并没有采用当下主流的“感知+规划”的分模块智驾结构,而是和Momenta将其整合进一个大模型,云端算力为2.5EFLOPS。
这样的好处显而易见,除了减少手写规则,有利于实现全局流程最优,其训练的上限也较高。
智己敢宣称自家“一段式端到端智驾大模型”断代领先,背后还有一个重要原因就是这款大模型具备人工智能生成的“直觉能力”,即也可以理解为智驾从“像人”进化到了“成为人”。
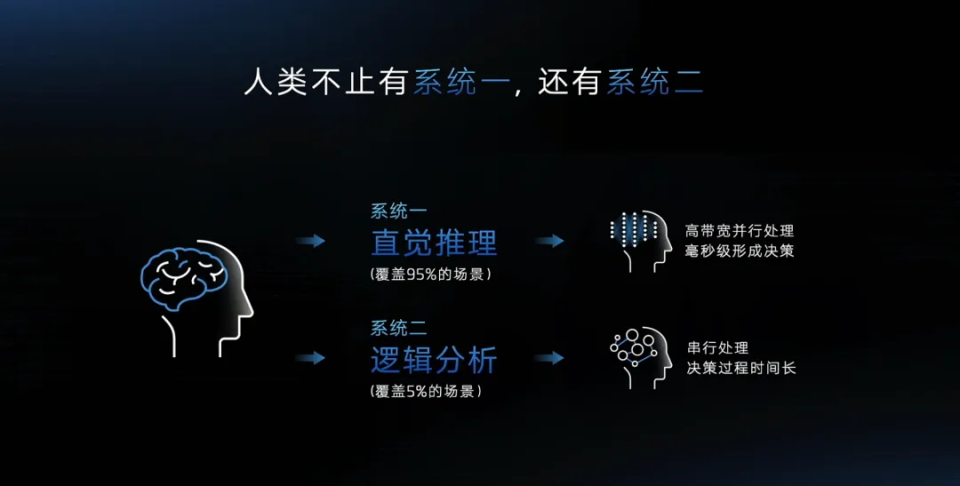
直觉是人类才有的特质,官方称IM AD3.0会以更接近人脑结构的思考方式,生成本能反应主导的直觉决策能力。
尤其是在前车突然刹停和人车混流的无保护左转场景的情况下,传统的智驾系统会像机器般执行原有指令“傻等”,但IM AD3.0会像老司机一样观察两侧路况,并伺机变道。
如果碰上车道有水坑的情况下,IM AD3.0也会做出绕行水坑,而不是继续执行车道保持,从水坑上驶过。
在训练这套智驾系统的过程中,智己还采用了“长短期记忆模式”架构。

简单来说,就是将智驾大模型的数据处理分为短期记忆和长期记忆两种模式。短期记忆可以实现以天为单位的迭代,快速验证优质数据;长期记忆则是周级迭代优质数据,对数据进行质量评估后,把优质数据输出,应用于端到端大模型。
“长短期记忆模式”其实就是在模仿人脑“直觉推理+逻辑分析”的问题处理方式,可以在模型训练成本节省10-100倍的同时,大幅提升迭代速度。
都得需要安全机制兜底
其实从智驾领域普遍的方案来看,分段式端到端是目前行业的主流方案。
分段式的大模型,感知端用一个模型,控制决策规划用一个模型,用两个模型来代替One Model,也是目前主流的端到端路线,像小鹏的XNGP、华为ADS3.0都是分段式端到端的方案。
而所谓一段式端到端大模型,就是取消了分模块智驾结构,将感知与规划整合进一个大模型,一个完整的神经网络减少了中间结构化感知结果的传递,从原始数据输入到规划路径输出,实现了信息无损传递,像车辆的颜色、司机的性别、车辆的状态等,体验更类人,性能上限更高。

所以不难看出,在智驾追求上,One Model大模型要比分段式大模型要好的多,因为信息的无损传递,上限也变得极高。
当然,从两段式端到端、模块化端到端到单一神经网络模型的One Model端到端的进程中,越往后,难度也越大。这也是为什么目前行业选择的主流方案是分段式端到端的原因。
就像不久前,极越汽车在其智驾发布会上说的那样“One Model的一段式端到端,好像可以用数据来解决所有问题。那为什么还是选择两段式端到端?”
因为出于安全因素的考虑。
虽然“One Model”的一段式模型,上限极高,但下限同样也很低。要知道通过一套神经网络模型来进行驾驶行为决策,这过程就像“黑盒”一样,很难控制系统输出的内容。
而且它也缺乏透明度,工程师很难修复系统中存在的决策漏洞,并不能保证绝对的安全,也就说,一段式方案面临更难的长尾问题。
但这也并不意味着,目前一段式端到端的方案就无法落地。
尽管AI模型存在不可控性,可能会做出一些违背物理规律的结论推导。所以这个时候,就不能仅靠“直觉”了,它还需要加入“逻辑”加以纠正。在一段式的前提下,加入“安全逻辑网络”来兜底,保证直觉决策的安全性。
这也对应智己汽车的方案,“一段式端到端+安全逻辑网络”,通俗的来说就是人脑的直觉推理+逻辑分析两个部分,正好对应智己给出的“长短记忆”两个系统结合。
而且智己汽车也不是第一个这么干的,在此之前,最先在智驾领域应用这种方案的是理想,其搭载的E2E(端到端大模型)+VLM(视觉语言模型)分成系统一和系统二,组成了“快慢”系统,两个系统相互配合,构成了人类认知和理解世界、做出决策的基础。
不难看出,两家在理念上极为类似,不过,在技术框架上有所区别。
理想的系统一是E2E端到端;系统二是VLM视觉语言模型,VLM在一些复杂场景下,会对E2E进行指导,像是一位陪驾的老司机,因为是一套视觉语言模型,所以运作频率相较于E2E是一套慢系统。
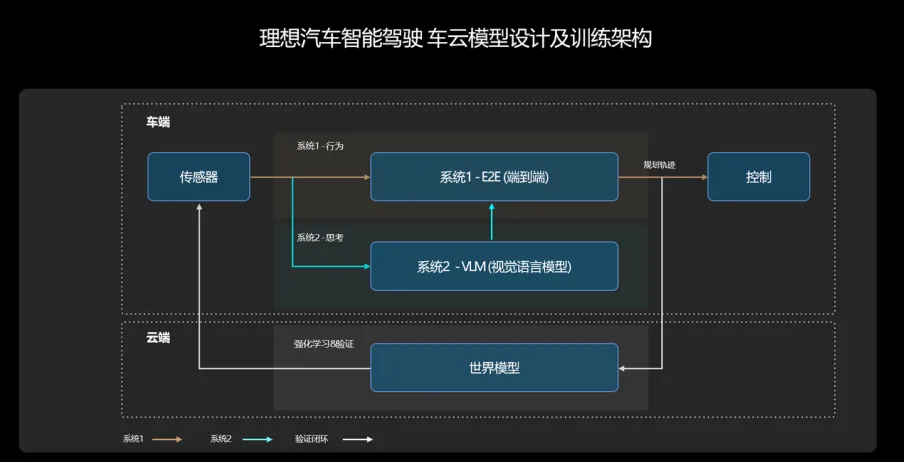
理想E2E端到端是系统一,作为主决策者,VLM视觉语言模型,当作系统2,可以理解为系统1的“冗余”,VLM在一些复杂场景下,会对E2E进行指导,像是一位陪驾的老司机,因为是一套视觉语言模型,所以运作频率相较于E2E是一套慢系统。
VLM视觉语言模型具备一些逻辑思考的能力,会在一些复杂情况下验证“端到端”的决策,最终实现车辆的兜底或控制。
而智己对应的方案“长短记忆“模式,长期记忆是通过E2E来完成,作为主决策者。
而智己上安全逻辑网络,就不是视觉语言模型了,而是一套由规则构成的逻辑算法,这套系统使用串行处理方式,对数据进行验证,实现算法迭代。

可以理解为对某个场景,某个功能模型的小版本演化,可以达到快速迭代试错目的,然后经过验证过的好的算法和数据,会在一段时间的积累后应用在“长期记忆”,即最终的端到端大模型上。
不难看出,虽然两家采用了不同的技术框架,但在理念上是殊途同归,而且都需要一套安全网络进行兜底。
所以再性感的智驾技术方案,没有足够的安全都是空中楼阁,技术路线或许没有标准答案,不断解决掉长尾问题,才是智驾的最优解。



