





2025智源大会,新一代「面壁小钢炮」 MiniCPM4.0 端侧模型发布。一款 8B 稀疏闪电版,带来端侧性能创新式大跃升;一款 0.5B 实力演绎以小博大,适配广泛终端场景。
第四代小钢炮推出了首个原生稀疏模型,5%的极高稀疏度加持系统级创新技术的大爆发,让长文本、深思考在端侧真正跑起来,宣告了端侧长文本时代到来!220倍极限加速,一半参数翻倍性能的强悍表现,一如既往带来端侧基模最极致表现。
一
代号「前进四」,小钢炮 MiniCPM4.0 树立起新一代端侧基础模型标杆,带来超预期的速度、性能、存储与端侧部署表现。
前进四,代表极致的速度提升:面对此前端侧模型长文本「龟速推理」业界难题,MiniCPM 4-8B 「闪电稀疏版」,采用了新一代上下文稀疏高效架构,相较于 Qwen-3-8B、Llama-3-8B、GLM-4-9B等同等参数规模端侧模型,实现了长文本推理速度 5 倍常规加速以及最高 220 倍加速(显存受限极限场景下测出),真正让端侧模型长文本推理实现了「快如闪电」的质变。此外,注意力机制上实现了高效双频换挡,长文本用稀疏,短文本用稠密,切换快如流。

前进四,代表性能的大迸发:MiniCPM 4.0 推出端侧性能“大小王”组合,拥有 8B 、0.5B 两种参数规模,延续「以小博大」特性,实现了同级最佳的模型性能。其中,MiniCPM 4.0-8B 模型为稀疏注意力模型,在MMLU、CEval、MATH500、HumanEval等基准测试中,以仅 22% 的训练开销,性能比肩 Qwen-3-8B、超越Gemma-3-12B。MiniCPM 4.0-0.5B 在性能上,也展现出惊人的以小博大—— 相较更大的Qwen-3-0.6B、Llama 3.2, 仅2.7%的训练开销,一半参数性能翻倍,并实现了最快 600 Token/s 的极速推理速度。
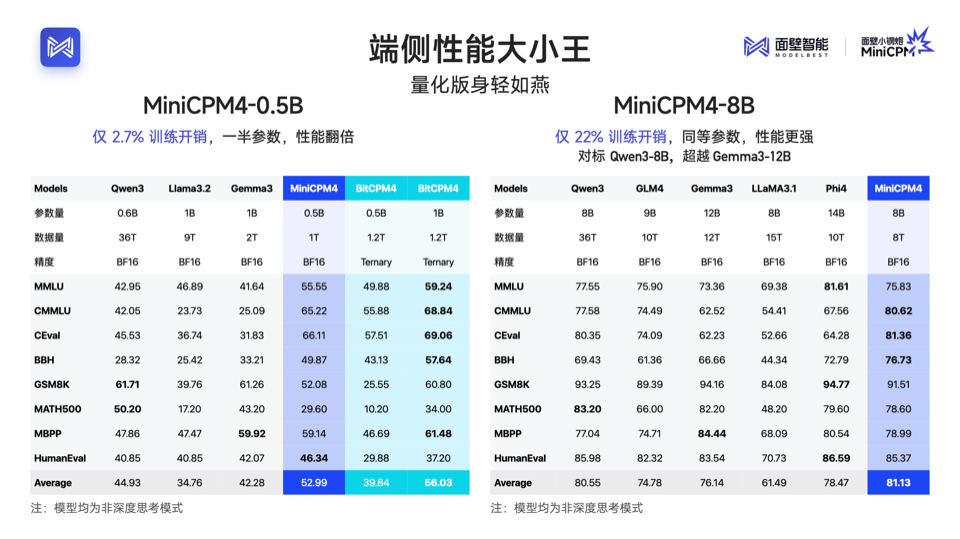
前进四,代表端侧部署的极致优化:MiniCPM 4.0 持续卫冕全球最强端侧模型,并进一步实现了长文本缓存的大幅锐减,在 128K 长文本场景下,MiniCPM 4.0-8B 相较于 Qwen3-8B 仅需 1/4 的缓存存储空间。量化版身轻如燕,高达90%的模型瘦身,性能依然十分稳健。在速度、性能飙升的同时,又做到了模型极致压缩,让端侧算力不再有压力,成为业界最为友好的端侧模型。
在应用上,端侧长文本的突破带来更多可能。基于 8B 版本,团队微调出两个特定能力模型,分别可以用做 MCP Client 和纯端侧性能比肩 Deep Research 的研究报告神器 MiniCPM4-Surve。

与此同时,面壁智能也携手诸多行业伙伴,持续推动 MiniCPM 4.0 模型适配及应用拓展。截止目前,MiniCPM 4.0 已实现 Intel、高通、MTK、华为昇腾等主流芯片的适配。此外, MiniCPM 4.0可在 vLLM、SGLang、llama.cpp、LlamaFactory、XTuner等开源框架部署。同时加强了对 MCP的支持,且性能超过同尺寸开源模型( Qwen-3-8B),进一步拓展了模型开发、应用潜力。
二
首个原生稀疏模型的发布,让长文本、深思考在端侧奔跑真正成为可能。由于传统稠密模型的上下文窗口受限,长文本又提出比较高的内存和算力需求,过去在端侧场景几乎不可用。对这一问题的解决,至关重要,又比较艰难,需要贯穿架构层、算法层、系统层、数据层的系统级层层优化。
长文本是模型发展的重要技术发力点,可以保证生成文本的连贯性和一致性。在端侧需求更甚,因为用户终端上有大量的用户个人信息上下文,只有处理好这些上下文,才能真正做出最懂用户的个人助理产品。而这些个人信息上下文,隐私性非常高,譬如聊天记录、位置信息等,只有完全端侧实现才能保证个人信息安全。终端设备对世界的感知,也同样需要在端侧发生,典型的案例是辅助(自动)驾驶,光学摄像头和其它传感器的感知信号必须要在本地处理和理解,避免延迟和丢包。而感知所需要的多模态模型能力,对长上下文的要求是极其夸张的,模型想要记住一路摄像头 10 分钟之类的连续视觉信号,供实时推理使用,就已经需要超过 100K 的上下文长度了,还不考虑多路及声音和其它传感器所代表的模态信号。
这次行业首例全开源的系统级上下文稀疏化高效创新,具体来说是基于新一代稀疏注意力架构 InfLLM 做了模型创新,并通过自研端侧推理三级火箭,自研 CPM.cu 极速端侧推理框架,从 投机采样创新、模型压缩量化创新、端侧部署框架创新 几方面,带来 90% 的模型瘦身和极致速度提升,最终实现端侧推理从天生到终生的高效丝滑。同时,在综合性能的极限推进上,点滴领先背后都是「十年之功」的积累,新一代模型的发布也是研究团队技术创新的集大成呈现。
1、【架构高效】新一代稀疏注意力架构 InfLLM ,速度准度双效提升
引入稀疏注意力架构为什么在当下如此重要?一是长文本处理、深度思考能力成为人们对大模型愈来愈迫切的需求,而传统稠密模型上下文窗口受限;二是稀疏度越高,计算量越小,速度越快越高效。DeepSeek等明星项目以稀疏模型架构撬动的“高效低成本”收益愈益得到认可。端侧场景天然因算力限制,对效率提升与能耗降低要求则更加迫切。
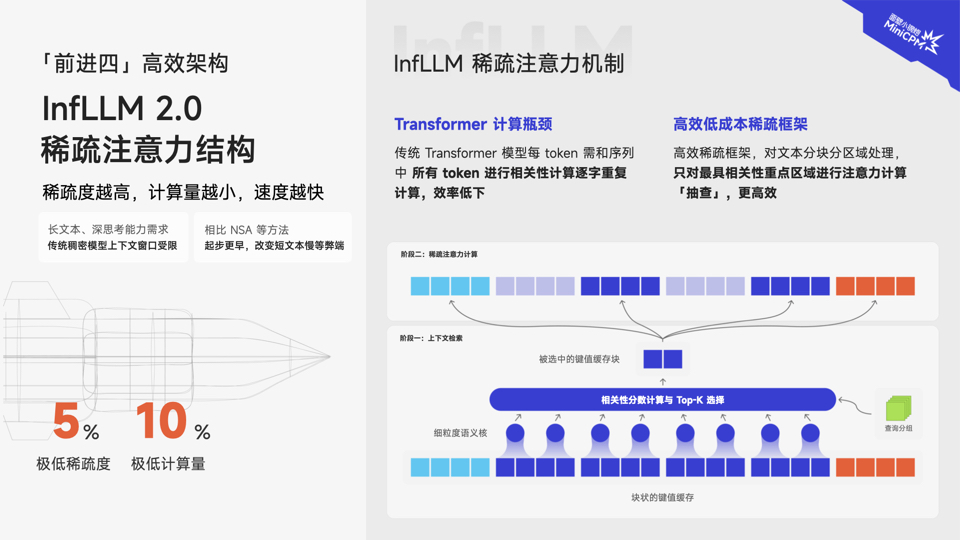
传统 Transformer 模型的相关性计算方式是每个词元都需要和序列中所有 词元进行相关性计算,造成了较高的计算代价。MiniCPM 4.0 模型采用的 InfLLMv2 稀疏注意力架构改变了传统 Transformer 模型的相关性计算方式,到分块分区域高效「抽查」——即对文本进行分块分区域处理后,通过智能化选择机制,只需对最有相关性的重点区域进行注意力计算“抽查”,摆脱了逐字重复计算的低效。InfLLMv2 通过将稀疏度从行业普遍的40%-50%,降至极致的 5%,注意力层仅需1/10的计算量即可完成长文本计算。且对算子底层重写,进一步加速提升,并使得对文本相关性精准性大大提升。
值得一提的是,DeepSeek 使用的长文本处理架构 NSA(Native Sparse Attention)也引用并采用了与InfLLM相同的分块注意力计算思路,但其对于短文本的推理较慢,InfLLMv2 则很好的解决了NSA在短文本推理上的短板。
针对单一架构难以兼顾长、短文本不同场景的技术难题,MiniCPM 4.0-8B 采用「高效双频换挡」机制,能够根据任务特征自动切换注意力模式:在处理高难度的长文本、深度思考任务时,启用稀疏注意力以降低计算复杂度,在短文本场景下切换至稠密注意力以确保精度与速度,实现了长、短文本切换的高效响应。

2. 【推理高效】推理高效三级火箭,自研全套端侧高性能推理框架
在推理层面,MiniCPM 4.0 通过 CPM.cu 自研推理框架、BitCPM 极致低位宽量化、ArkInfer自研跨平台部署框架等技术创新,实现了极致的端侧推理加速。
CPM.cu 端侧自研推理框架,做到了稀疏、投机、量化的高效组合,最终实现了 5 倍速度提升。其中,FR-Spec 轻量投机采样类似于小模型给大模型当“实习生”,并给小模型进行词表减负、计算加速。通过创新的词表裁剪策略,让小模型专注于高频基础词汇的草稿生成,避免在低频高难度词汇上浪费算力,再由大模型进行验证和纠正。
BitCPM 量化算法,实现了业界SOTA级别的 4-bit 量化,并成功探索了 3 值量化(1.58bit)方案。通过精细的混合精度策略和自适应量化算法,模型在瘦身 90%后,仍能保持出色的性能表现。
ArkInfer自研跨平台部署框架,面向多平台端侧芯片极致优化,实现了大平台的高效投机采样和限制编码,确保端侧多平台 Model zoo 丝滑使用。

3、【训练+数据高效】打造大模型光刻机,优化科学化建模产线
为什么面壁总能带来同等参数、性能更强,同等性能、参数更小的先进模型?大模型制程看得见的领先背后,是无数看不见的技术积累与严苛标准;是点点滴滴细节的精益求精。
区别于业界普遍采用的“大力出奇迹”路线,面壁智能坚持以「高效」为核心的技术路径。对大模型科学化的探索,贯穿从数据、训练、学习、推理等层层流程,实现了研发投入产出比的最大化。
好数据才有好模型,高效构建高质量数据,是高质量模型的基本盘。面壁在这一领域拥有诸多创新方法,并且悉数开源。譬如,Ultra-FineWeb 高知识密度数据筛选机制,用“半成品加工法”来构造万亿数据,通过先训一个“半熟”模型, 再用新数据快速微调,如同预制菜快出成果,最终实现 90% 的验证成本降低。在大规模数据质检方面,利用轻量化的 FastText 工具,处理 15 万亿 token 数据仅需 1000 小时 CPU 时间。同时,UltraChat-v2 合成了包含数百亿词元的高质量对齐数据,在知识类、指令遵循、长文本、工具使用等关键能力上进行定向强化。在高质量数据与高效训练策略的加持下,相比同尺寸开源模型,MiniCPM 4.0-8B 仅用 22% 的训练开销,即可达到相同能力水平。
在训练策略上,MiniCPM 4.0 应用了迭代升级后的风洞 2.0 方案(Model Wind Tunnel v2),通过在 0.01B-0.5B 小模型上进行高效实验,搜索最优的超参数配置并迁移到大模型,相比此前的 1.0 版本,风洞 2.0 将配置搜索的实验次数降低 50%。针对强化学习训练中的负载不均问题,Chunk-wise Rollout 技术通过分段采样策略,确保 GPU 资源的高效利用。工程层面还采用了 FP8 训练和 MTP 监督信号等前沿技术,进一步提升训练效率。

此次 MiniCPM 4.0 的发布,是面壁智能持续探索高效大模型道路上的又一重要里程碑,通过多维度、高密度的优化,真正做到行业唯一的端侧可落地的系统级软硬件稀疏化高效创新。这也是面壁获得来自社区广泛认同的本因。截至目前,面壁小钢炮 MiniCPM 系列全平台下载量累计破 1000 万。未来,面壁智能还将基于「大模型密度定律 Densing Law」,持续提高大模型的知识密度与智能水平,推动端侧智能高效发展与规模化产业应用。




